In this post, we’ll work though how we can maximize bulk insert throughput to Azure Table Storage using Azure Functions in a consumption plan.
In general when working with batch operations in Table Storage, the partition key strategy we choose is an important factor because operations on entities with the same partition key, can be applied as part of a TableBatchOperation. This supports up to 100 transactions in an atomic operation, which is good for throughput. While the approach we’ll cover here for bulk loading is equally applicable to scenarios where you can use batch transactions, we’re going to be working with a scenario when they can’t be used due to inserts targeting separate partitions.
Looking at the Scalability Targets for Azure Table Storage, the throughput limit is 20,000 transactions per second for a storage account, and 2000 per second for a single partition. As we’re dealing with different partitions, we don’t have to worry about the per-partition limit, so we’ll be targeting the 20,000 per second at the account level.
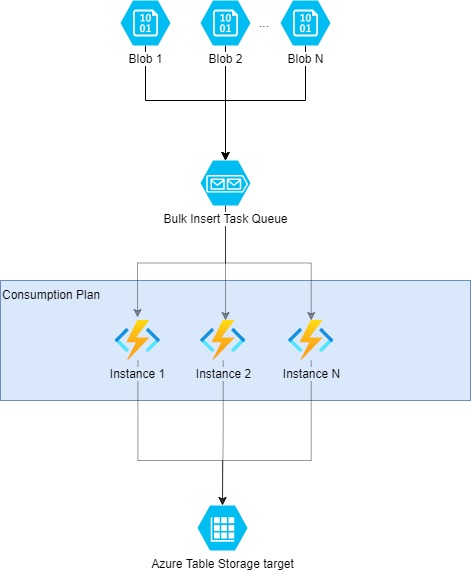
Architecture Overview
The key to maximizing bulk insert performance is parallelism, so the approach we’ll take is:
- break the dataset to load into Table Storage, into smaller chunks as CSV blobs in Azure Blob Storage
- queue up a message for each blob
- have a queue trigger Azure Function to load a blob into Table Storage
- we’ll use an
Upsertoperation for each record rather than anAdd- should a message retry, this gives us resiliency so that doesn’t subsequently fail with conflicts
- we’ll use an
Test setup
The full code can be found in my AdaTheDev.TableStorageBulkInsert GitHub repo. The main Azure Function implementation is here
I generated dataset of 10 million records containing a GUID to use as the partition key and an incrementing number. The entity has 2 custom properties - 1 to also hold the GUID, and another for the integer. I split these over 400 CSV files of 25,000 records each, and uploaded them to Blob Storage.
Each test run used a test number which was appended to the destination table name to load the data into a new table each time. A record was written to a stats table for each file loaded for each test run, which included the start and end time to load that chunk of data into the destination table.
I used the same Azure Storage Account for all aspects of the test - blob, queue and table storage.
Where applicable, the key measurements I took, and how they were determined:
- Duration: (max end time) - (min start time) from the stats table for that test run
- Upserts/sec: total number of records loaded / duration (per above). See Peak transactions/sec for the peak storage account throughput measurement
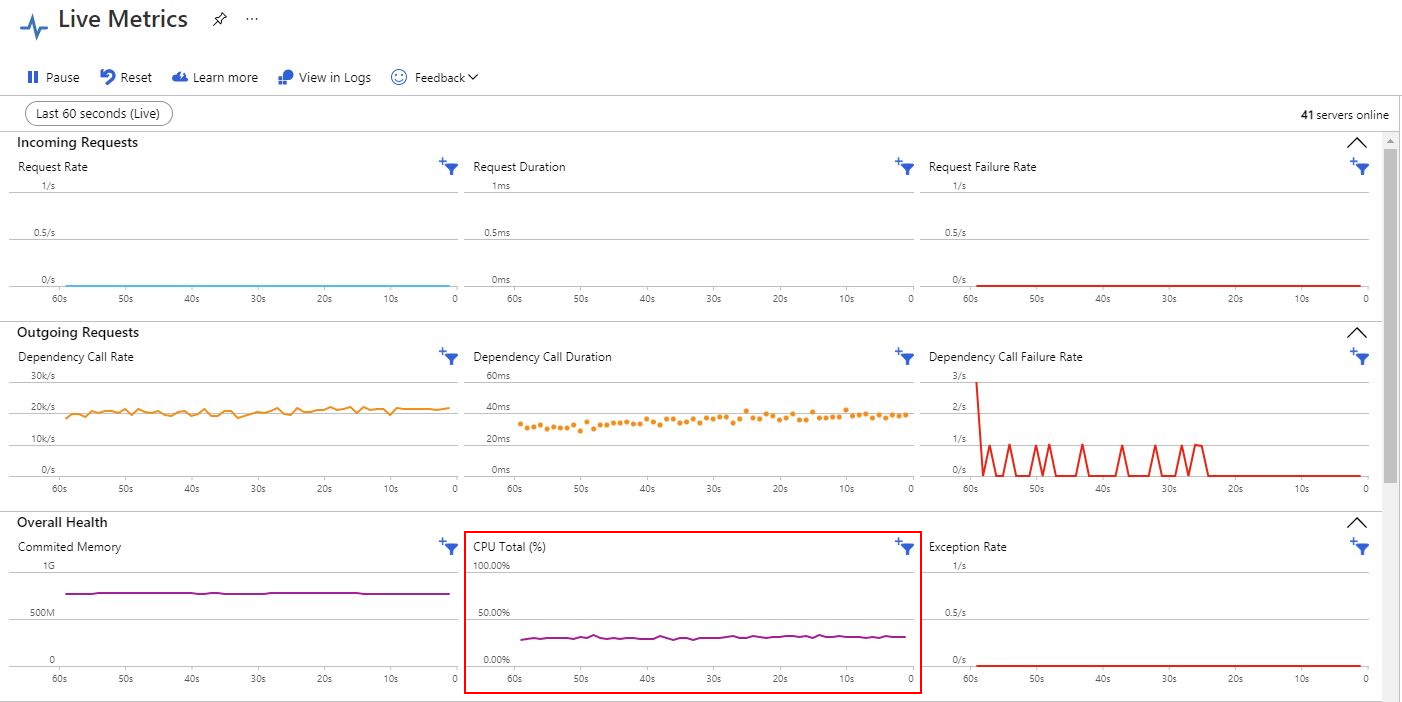
- Average CPU: from the “Live Metrics” for the Function App in the Portal (Monitoring side menu -> Log Stream -> Open in Live Metrics), as shown here:
- Peak transactions/sec: from the Metrics page for the storage account in the Portal, plotting the sum of transactions over the past 30 minutes and grabbing the max (minute level) then dividing by 60
The Live Metrics view is great to give a real-time view of the number of instances your Function App has scaled out to. If you want a way to monitor this over time and visualize in a chart, check out my previous post: Monitoring Azure Function Consumption Plan Scale Out
Controlling throughput
host.json
{
"version": "2.0",
"functionTimeout": "00:10:00",
...
"extensions": {
"queues": {
"batchSize": 1
}
}
}
The main things we set here:
- queue batchSize to 1 - this means each Function instance will only process a single message at a time. This means the level of scale out we set for the consumption plan, is the maximum number of files we want to process in parallel.
- functionTimeout to 10 minutes - the maximum for a consumption plan. Though we will be well within this with the file size we’ll be using.
Azure Function scale out options
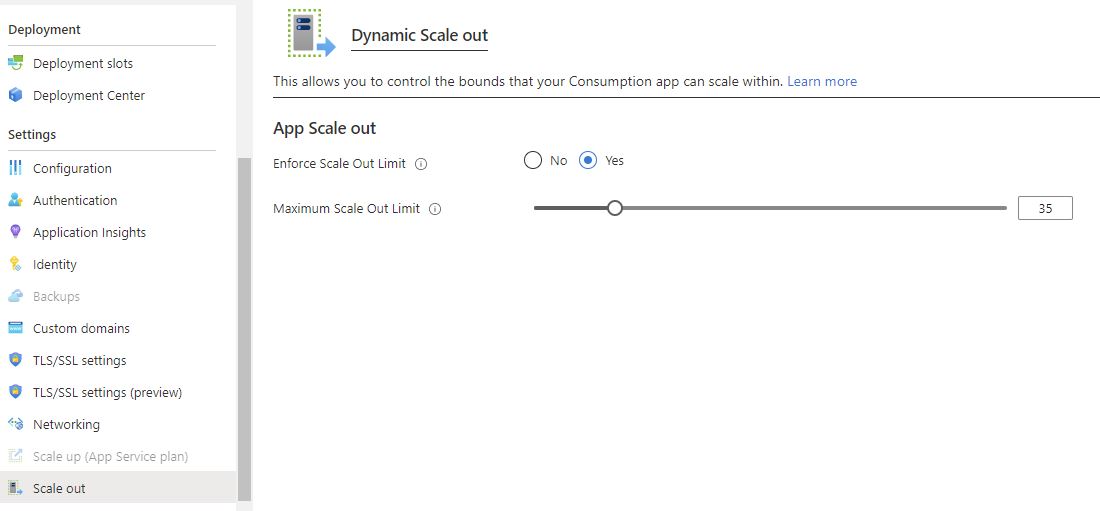 In the Azure Portal for the Function App, we can adjust the maximum number of instances that it will scale out to as shown above. Setting a higher value, will process more files in parallel and thus
increase bulk insert throughput to a limit.
In the Azure Portal for the Function App, we can adjust the maximum number of instances that it will scale out to as shown above. Setting a higher value, will process more files in parallel and thus
increase bulk insert throughput to a limit.
It’s important to determine a level of scale out appropriate to your environment. For example, if you’re loading in to a table in an Azure Storage account that is under load from a production system, you’ll likely want to choose a lower scale out so as not to start hitting the scalability limits mentioned above and affecting other parts of the system due to throttling of requests.
Also, it’s important to note, that sudden influxes of high volumes of transactions may not experience the full throughput available from Table Storage as per the official docs which states:
Azure Storage load balances as the traffic to your storage account increases, but if the traffic exhibits sudden bursts, you may not be able to get this volume of throughput immediately. Expect to see throttling and/or timeouts during the burst as Azure Storage automatically load balances your table. Ramping up slowly generally provides better results, as the system has time to load balance appropriately.
Test set 1 - 100,000 records - Identifying base-line for a single instance
The first thing we want to find out, is how to get the most out of a single Azure Function instance which gives us 100 ACUs (Azure Compute Units) per instance.
With scale out set to 1 in the Portal, I queued up 4 files for processing. The following results show the outcomes of changing the level of task parallelism for the Upsert operations,
using await Task.WhenAll(upsertTasks).
| Test Number | Parallel Upsert Tasks | Average CPU | Duration | Upserts/sec |
|---|---|---|---|---|
| 1 | 1 | 16% | 15m 30s | 108 |
| 2 | 10 | 67% | 2m 59s | 558 |
| 3 | 15 | 77% | 2m 19s | 717 |
| 4 | 20 | 97% | 2m 2s | 817 |
15 parallel tasks gave a good balance with some CPU headroom - so that’s what we’ll stick with for the rest of the tests as we ramp up volumes. We’re clearly a long way off the scalability limits, so next we’ll up the load and start to scale out.
Test set 2 - 1 million records
Ramping up to 40 files, this time I tried increasing the max scale out for the Azure Functions to load 1 million records in.
| Test Number | Max scale out | Duration | Upserts/sec | Peak transactions/sec |
|---|---|---|---|---|
| 5 | 10 | 3m 56s | 4238 | 6426 |
| 6 | 40 | 3m 11s | 5215 | 7985 |
It took a while for the number of instances to scale out in each case. For test 6, it reached 18 instances before the test finished so didn’t hit the maximum 40. Time to use a bigger dataset!
Test set 3 - 10 million records
This time, I queued up 400 files to process and stuck with max scale out of 40.
| Test Number | Max scale out | Duration | Upserts/sec | Peak transactions/sec |
|---|---|---|---|---|
| 7 | 40 | 12m 53s | 12930 | 16833 |
| 8 | 40 | – | – | – |
Test #7 took a short while to ramp up to 40 instances before some 503 responses started being returned from Table Storage - these were visible via the Live Metrics view. Table Storage
metrics for the storage account showed a record peak throughput for this run, of 1.01 million transactions in a 1 minute period:
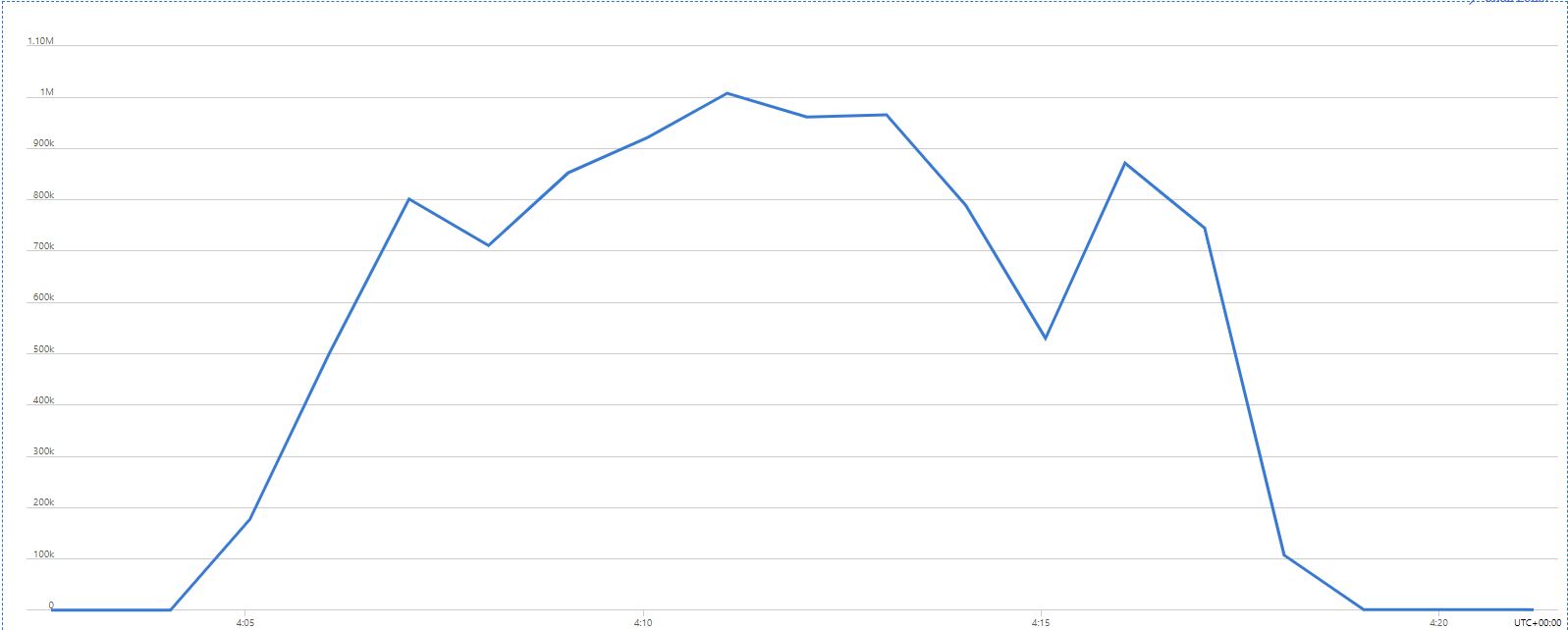
I ran Test #8 straight after to repeat it, before the instances scaled back down but abandoned the run when a handful of messages failed on the first attempt. They succeeded on retry, but by that point had thrown off the results for a clean run. I was clearly seeing an increase in throttling from Table Storage that were having an impact, so I lowered the scale out to 35 before moving on to the final tests.
| Test Number | Max scale out | Duration | Upserts/sec | Peak transactions/sec |
|---|---|---|---|---|
| 9 | 35 | 14m 42s | 11325 | 16597 |
| 10 | 35 | 11m 53s | 14013 | 16274 |
Test #9 was from a standing start - 0 instances at the start, and took a while to scale out to 35 instances.
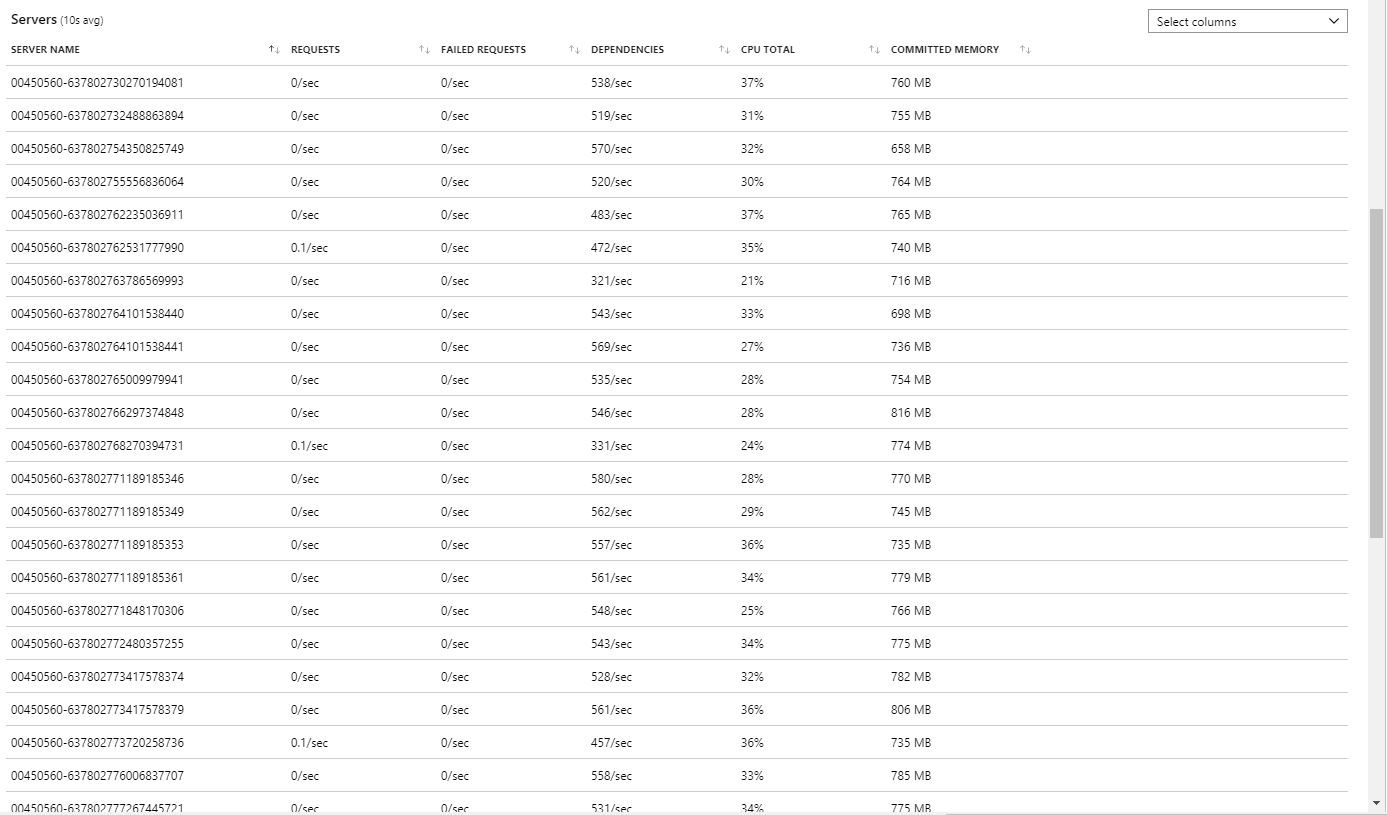
Test #10 was a re-run straight after, before the 35 instances could scale back in - these can all be seen doing work in the Live Metrics view, like this:
Scaling up to 100 million records
Based on the level of throughput we seen above, how long would bulk inserting 100 million records take?
100,000,000 / 14013 (upserts/sec) = 7136 seconds = approximately 1h 59m.
We do have scope to go a bit faster - I expect somewhere between 35 and 40 instances could be the level at which we’re not impacted by throttling, plus we could use a separate storage account for blobs and queues to that of table storage.
Summary
This approach gives a lot of flexibility for bulk loading data into Azure Table Storage, allowing us to choose a lower or higher rate of throughput depending on what best suits our needs. But not only that, using a consumption plan allows means we only pay for the resources we use while the functions are running, and when they are not processing data, there is no cost.