Suppose you want to write a query to find all products in your database that have a name beginning with “Long-Sleeve”. You’d more than likely use something like below (examples based on AdventureWorks LT sample database):
SELECT name
FROM SalesLT.Product
WHERE name LIKE 'Long-Sleeve%'
This produces a good execution plan, performing an index seek on the nonclustered index that exists on the name column. If you look at the seek operation, you’ll see the query optimiser has done a good job of ensuring an index can be used by looking at the seek predicate:

You’ll see what it’s actually done is converted the LIKE condition to a “>=” OR “<” query, searching for product names where the name >= “Long-Sleeve” and is < “Long-SleevF”.
Now, suppose you want to find all products where the name ends with “Tire Tube”. The immediate query that springs to mind is:
SELECT name
FROM SalesLT.Product
WHERE name LIKE '%Tire Tube'
The execution plan shows an index scan like below. Unfortunately, it’s not ideal as it’s not making good use of the index.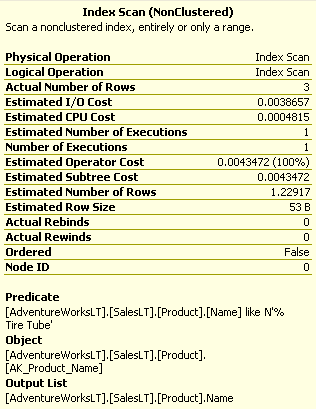
A way to optimise this scenario is flip the LIKE condition on its head, to get the wildcard at the end of the string being matched on. If you reverse the product name, and reverse the string being matched on you get the same results.
i.e.
SELECT name
FROM SalesLT.Product
WHERE name LIKE '%Tire Tube'
gives the same results as:
SELECT name
FROM SalesLT.Product
WHERE REVERSE(name) LIKE REVERSE('%Tire Tube') -- or in other words, LIKE 'ebuT eriT%'
Now that as it stands isn’t any better as it still can’t use an index. But add a computed column to reflect the reversed name column, and then add an index on that, then you soon can see the benefits.
-- Add a NameReversed column that is the Name column, but reversed
ALTER TABLE SalesLT.Product
ADD NameReversed AS REVERSE(Name)
-- Now index that reversed representation of the product name, and INCLUDE the original Name column
CREATE INDEX IX_Product_NameReversed ON SalesLT.Product(NameReversed) INCLUDE (Name)
Run the 2 queries side by side to compare like below:
SELECT Name FROM SalesLT.Product WHERE Name LIKE '%Tire Tube'
SELECT Name FROM SalesLT.Product WHERE NameReversed LIKE REVERSE('%Tire Tube')
Note I’m keeping the use of REVERSE just to make the condition a bit more readable for demonstration purposes.
The optimised, indexed computed column approach is using an index seek, compared to the original way that uses the index scan as shown below.
Trying this on a slightly bigger table (the AdventureWorks sample database Product table has only about 800 rows) highlights the difference further. In a table with approximately 50,000 rows, the cost of the original attempt (relative to the batch) showed as 98%. Leaving the relative cost of the computed column approach at 2%. The execution stats showed:
Original Approach
Cold cache: CPU=62, Reads=138, Duration=95
Hot cache: CPU=63, Reads=124, Duration=65
Indexed Computed Column Approach
Cold cache: CPU=0, Reads=28, Duration=28
Hot cache: CPU=0, Reads=2, Duration=0
Now imagine on a larger table with million of rows, how this optimisation would scale up…
As per usual, you need to consider the specifics of your situation as adding extra indexes etc. will add to database size and means there is more work to do when performing INSERTs/UPDATEs. If you identify you have a performance problem with a similar scenario, then this approach is at least something to consider.