Bulk Load To Azure Table Storage Using Azure Function Scale Out
Posted on February 14, 2022
(Last modified on February 13, 2022)
| 8 minutes
| 1518 words
| Adrian Hills
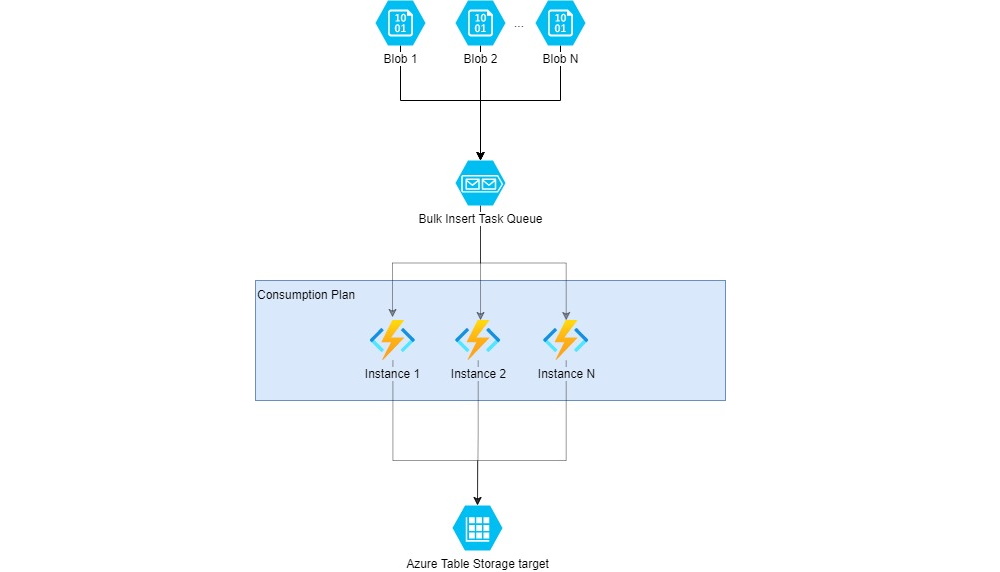
In this post, we’ll work though how we can maximize bulk insert throughput to Azure Table Storage using Azure Functions in a consumption plan.
[Read More]Monitoring Azure Function Consumption Plan Instance Scale Out
Posted on January 29, 2022
(Last modified on February 13, 2022)
| 2 minutes
| 336 words
| Adrian Hills
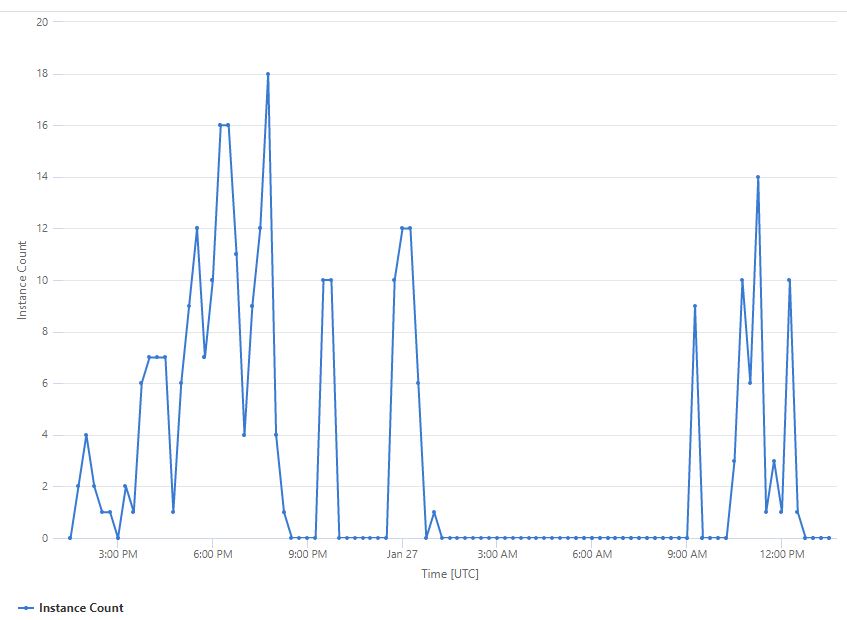
With the Consumption Plan hosting model for Azure Functions, we can take advantage of event-driven scaling to automatically spin up extra instances of a Function app based on
load. In this post, we’ll cover how you can view this in real-time and also how to chart the scaled-out instances retrospectively over time.
[Read More]E2E Testing Azure Functions
Posted on January 10, 2022
| 7 minutes
| 1457 words
| Adrian Hills
Scenario Recently I was working on a solution which included multiple Azure Function apps, with unit tests (xUnit) giving rapid feedback for discrete components across the solution in isolation. But the next step was to create some automated end-to-end (E2E) tests that exercised the behaviours of the solution as a whole.
The goal was to be able to get that feedback as early on in the development process as possible which meant being able to run those E2E tests against a local build on a dev machine when needed with minimal hassle, and in an Azure DevOps CI/CD pipeline, without requiring the Azure Functions to be deployed first.
[Read More]Troubleshooting Azure Function Consumption Plan Scaling
Posted on December 17, 2021
(Last modified on January 2, 2022)
| 5 minutes
| 924 words
| Adrian Hills
I recently encountered an issue with an Azure Function Event Hub trigger running on a Linux Consumption Plan, whereby events stopped being consumed by the trigger once it went to sleep. I learned a lot about consumption plan scaling and diagnosing what was going on, so in this post I’m going to share the key takeaways that I picked up as it was a bit of a journey.
Background: Azure Function Event Hub trigger stopped processing events This was in a low-throughput scenario for testing - so the rate of events coming into the Event Hub was low/sporadic.
[Read More]Samsung Gear Sport vs SWIMTAG - Swimathon 2018
Posted on April 29, 2018
(Last modified on January 2, 2022)
| 6 minutes
| 1072 words
| Adrian Hills
This post is a bit different to my normal ones in that it’s not my usual ramblings about something software development related. Instead, it’s a cross between a write-up of my taking part in Swimathon 2018, and a side-by-side comparison of how my swim was tracked by 2 different bits of kit: a Samsung Gear Sport and SWIMTAG. For those that sponsored me, this is proof that I held up my side of the deal!
[Read More]Getting started with SignalR
Posted on October 11, 2016
(Last modified on January 2, 2022)
| 3 minutes
| 480 words
| Adrian Hills
Follows on from previous post: Real-time SignalR and Angular 2 dashboard
I had a couple of questions from someone who forked the project on GitHub and is using it as the basis for their own custom dashboard, which reminded me that there are a few key things I picked up on my learning journey that I should share. These are primarily focused around SignalR aspects.
An instance of a SignalR hub is created for each request A single instance is not shared across all clients connected to that hub.
[Read More]Real-time SignalR and Angular 2 dashboard
Posted on October 7, 2016
(Last modified on January 2, 2022)
| 4 minutes
| 722 words
| Adrian Hills
tl;dr Check out my new SignalRDashboard GitHub repo
Followup post: Getting started with SignalR
For a while now, I’ve had that burning curiosity to do more than just the bit of hacking around with SignalR that I’d previously done. I wanted to actually start building something with it. If you’re not familiar with it, SignalR is a:
…library for ASP.NET developers that makes developing real-time web functionality easy.
It provides a simple way to have two-way communication between the client and server; the server can push updates/data to any connected client.
[Read More]dm_exec_query_plan returning NULL query plan
Posted on August 12, 2014
(Last modified on January 2, 2022)
| 5 minutes
| 878 words
| Adrian Hills
I recently hit a scenario (SQL Server 2012 Standard, 11.0.5058) where I was trying to pull out the execution plan for a stored procedure from the plan cache, but the query shown below was returning a NULL query plan:
[Read More]70-486 Developing ASP.NET MVC 4 Web Applications
Posted on September 19, 2013
(Last modified on January 2, 2022)
| 3 minutes
| 635 words
| Adrian Hills
Last week I passed the 70-486 Microsoft exam - Developing ASP.NET MVC 4 Web Applications, so thought I’d knock up a quick post on my experience and what materials I found useful as part of my preparation.
Going into this exam, I had just over a year and a half’s commercial experience using ASP.NET MVC 2 & 3. Before that, I had experience in ASP.NET and prior to that, when dinosaurs still roamed, classic ASP.
[Read More]SQL Server 2008 R2 in-place upgrade error
Posted on June 5, 2013
(Last modified on January 2, 2022)
| 1 minutes
| 210 words
| Adrian Hills
Today I encountered the following error during the process of performing an in-place upgrade of a SQL Server 2008 instance to 2008 R2:
The specified user 'someuser@somedomain.local' does not exist
I wasn’t initially sure what that related to - I hadn’t specified that account during the upgrade process so I went looking in the Services managemement console. The SQL Server service for the instance I was upgrading was configured to “Log On As” that account and it had been happily running prior to the upgrade.
[Read More]